
Applications of Machine Learning are all around us today:
- Alexa, the Virtual Assistant from Amazon.
- Watson, the IBM computer that plays Jeopardy.
- Self Driving Cars from Tesla.
- Google Maps software that can predict congestion.
- Online Recommendation engines that suggest to the user what to browse or buy.
- Advanced Medical Diagnostics.
- Text-to-speech conversion
- Speech-to-text conversion.
- Translation engines.
- Facial Recognition Systems used for or tracking down criminals.
- Facial Recognition for Access control for high-security premises,
- Facial Recognition to prevent minors from using adults’ accounts for online gaming.
All these and many more applications are based on Machine Learning.
What is Machine Learning?
What is machine learning? How does it relate to the other buzz words we hear daily – Artificial intelligence and Data Science?
Artificial intelligence (AI) is a wider term. It refers to the set of tools that makes computer applications work intelligently.
Machine learning is the most prominent area within AI. Robotics is another. There are no sharp boundaries, however.
Machine learning also overlaps with the disciplines of computer science and statistics.

Machine Learning can be defined as the set of tools that helps us to draw inferences from data and make predictions.
Human beings learn through formal education, social interactions, and experience.
Machines learn using data.
Machine learning gives applications the ability to learn from data and improve their accuracy over time without being explicitly programmed to do so. Applications can identify patterns in existing data and can apply those patterns to make inferences on new unseen data.
The performance of the application depends on the quality of data it works on.
With growing big data, availability of more powerful and inexpensive computing power, machine learning applications are getting better.
Machine Learning Model
Machine learning involves representing a real-world process as a statistical model. The model uses data from the real-world.
The algorithm trains the model to find patterns and features on large amounts of data. It can then use those patterns to make decisions or predictions.
For example, a Weather Prediction Model works on data of Weather conditions. Its outcome could be, for example, predicting whether it will rain tomorrow.
There are several types of Machine Learning Models like:
Linear Regression
Logical Regression
Decision Trees,
Neural Networks, etc.
Deep learning models use neural networks. These are best for use cases involving Computer vision and Natural Language Processing (NLP).
These models can scan through huge amounts of images and text data and identify features automatically.
Some example applications of deep learning models are Facial Recognition systems, Self-driving vehicles, Language translators, Digital assistants.
The choice of the machine learning models depends on the use case and the amount of data required,
Machine Learning Types
There are three principle ways in which machines learn –
1. Reinforcement Learning
In this type of machine learning, the algorithm does not train the model using sample data. Instead, it learns by trial and error. A sequence of successful outcomes reinforces the learning and it is presented as a solution. This often involves complex mathematics and game theory.
An example is a chess-playing application like IBM Deep Blue that is able to find the next best move by trial and error.
2. Supervised Learning
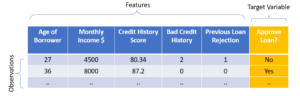
In this method, training data is used to train the model. The data is organized in table form. Each row is an observation. Columns are attributes or features for the observations.
One of the columns is the Target variable with values or ‘Labels’. The aim of the model is to find patterns – how the feature columns affect the value in the target column we are interested in.
An example application shown here uses a dataset where the observations are loan applications. There are some features in this data – like age of the borrower, monthly income, credit history score, bad credit history, and previous loan rejections. The target variable here is a categorical variable that can have a value of either ‘Yes’ or ‘No’. The problem here is of Classification – ‘Yes’ or ‘No’.
Training and Testing the Model
The labeled data is segmented into Training and Testing data (usually in a ratio decided, like 70:30).
The model is then trained on the training data.
Testing data is used to test the model to see how the labeled fields in the testing data compare with those predicted by the model.
Evaluating Performance
The accuracy of the model is determined by how many observations are classified correctly.

However, there are other performance criteria that may be more important in certain classification problems. In a use case of cancer diagnostics application, the performance criteria would be sensitivity. It should minimize false negatives, i.e have minimum cases where a patient who is having cancer is classified as not.
In the case of an application identifying spam, specificity should be more important. The model should minimize false-positive cases, i.e minimize sending good emails to the spam folder.
There can also be use cases where the target variable is a continuous variable, rather than a categorical one. In that case, it becomes a problem of Regression rather than classification. In this case, the performance would be determined by accuracy, i.e how close are the predicted values to actual ones.
The model can be fine-tuned to get the best performance by running several iterations on the testing data.
After it is trained up to the performance level required, it is ready to work with new data.
An example application is an application for identifying handwritten characters. The machine learning model is trained on thousands of samples of digitized samples of handwritten characters. Then it can identify characters from new data.
3. Unsupervised Learning
Unsupervised machine learning is when the machine learns without supervision. The algorithms work with much larger amounts of data and without human intervention. The data used does not have Labels. It may be too huge an effort to label data in many use cases.
This type of learning is suitable for use-cases requiring Clustering, Anomaly detection, or identifying Associations in the data. It is not used so much for decision-making or prediction.
Clustering is useful when the objective is to find how the data may be grouped based on certain features. The model finds clusters without being told to find some labeled clusters. For example – identifying clusters of patients with similar features who are vulnerable to disease.
Anomaly detection is used to find Outliers or Exceptions, like Fraud Detection applications.
Association is used in cases like Market Basket Analysis or recommendations for Associated products (usually bought together).
Very often, the applications work with data in real-time to find patterns that humans would most definitely miss.
An example of unsupervised learning is an application that Classifies the various categories of objects on the road for a Self-driving car. This would involve processing thousands of images of objects and vehicles. This would not be suitable for supervised learning at all.
Challenges
Artificial Intelligence systems are getting smarter with increasing computing power and advancement in learning algorithms. This has also thrown up some challenges.
The models are mostly black boxes that do the required job, but what is under the hood is mostly unknown. How do they make certain decisions or predictions? The algorithms driving these decisions may be biased or manipulated – unintentionally or deliberately. They could misuse international data regulations.
There are fears that big tech players controlling these algorithms might use them to manipulate public opinion and influence outcomes that have a huge impact – election results, for example.
Explainability is therefore an emerging requirement for these algorithms. That would assuage the customers and users of this technology to some extent.