
What are Recommendation Engines?
When you are looking for a product or service, you either go search for it or follow a recommendation made by someone who has used it. Very often when you are shopping at a store, a smart salesman would recommend stuff to you to help with your buying decision or to upsell.
Similarly, when you consume content or buy stuff online, you either search for it using a search engine or follow an online recommendation. These recommendations are generated by recommendation engines that are automated programs playing the role of that smart salesman.
This blog gives an overview of what recommendation engines are and how they work. I have used the term ‘product’ throughout this blog, but it is meant to represent both e-commerce products and online content.
Overview
Major e-Commerce sites have proprietary recommendation engines that run machine learning algorithms on data about consumers and products to generate recommendations.
These engines filter and narrow down the options to what might interest you and what is selling. The recommendations can be personalized. For example, the videos recommended by Youtube based on your viewing history, or Amazon recommending products similar to what you purchased earlier.
They can also be non-personalized like Amazon’s “Frequently bought together” and “Customers who bought this item also bought” recommendations. These are based on what other consumers have frequently bought along with the product you are exploring.
Benefits
These recommendations are helpful for the consumer as they help make the buying decision. This saves the consumer from having to explicitly search for every option. It makes a positive user experience for the consumer.
For the provider or seller, these recommendations help to boost their traffic, customer engagement, click-through rate (CTR). They provide up-sell and cross-sell opportunities to boost the average order value (AOV) and revenue. Positive customer experience leads to customer retention and brand loyalty.
According to research by a solution provider Baralliance, “product recommendations account for 31% of e-Commerce revenues”.
Filtering Data
The data that recommendation engines use to generate recommendations include explicit data. This includes product ratings, likes, and dislikes of past purchases.
Implicit data is gathered from the user’s browse sessions, clicks, and purchase history. All this is linked with the user’s profile information.
The recommendation engines use filtering algorithms that use content-based filtering, collaborative filtering, or a combination of both. They make use of data of product attributes and may also use domain knowledge around the products.
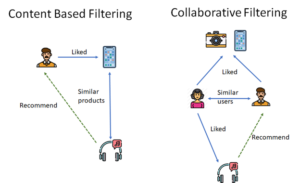
Content-based Filtering
This method filters products based on the user preference data to recommend products similar to those purchased or like in the past. It is based on the assumption that a user is more likely to buy a product that is similar to what the user has liked in the past.
The limitation of this method is that there must be a significant amount of user-preference data to work with. This presents an issue of ‘cold start’ when there is close to nil history available on the user’s preferences. To get around this, the e-commerce sites recommend the best-selling products to a new user. As the user history starts building, the recommendations get more personalized.
Also, a user’s preferences vary across the categories of the product. So, using the preference information in one category of products to recommend one in another category is not likely to produce good recommendations.
Collaborative Filtering
This method is based on the assumption that users with similar profiles and preferences would tend to buy similar products. For example, if user1 liked products A and B, user2 liked products A, B, and C, it is highly likely that user1 would like product C.
Two approaches that can be used for collaborative filtering are:
Lookalike users
In this approach, the preference histories of users are analyzed. The result is matrices of user similarity scores. A product that user-1 liked can be then recommended to user-2 having a high similarity score with user-1. Analyzing lookalike users in pairs is computationally expensive. Moreover, individual user preferences are subjective and change with time.
Lookalike products
In this approach, similarity matrices are created for products based on their attributes. It is much less expensive to perform product pair comparisons than user pairs. Once similarity scores between products are obtained in a matrix, a user can be recommended a product with high similarity to one that the user bought.
Identifying Similarities
The recommendation algorithms compare product attributes to establish product similarity. However, the comparison is more difficult in the case of products like books and movies, as the product features are not directly available. A common comparison, in this case, is the genre. However, these are not often labeled and a movie or a book may cut across more than one genre.
To address this issue, the classification algorithms use a data science technique called Natural Language Processing (NLP). They use NLP on the text of the plot description of the movie, the introduction text in the case of a book, or the book content itself.
This processing aims to find the most common words or terms between product description texts. The frequency of common terms in the texts can be used to represent the texts as data vectors. An indicator called cosine similarity indicates the similarity between the vectors. It is the cosine of the angle between two vectors and is usually a number between 0 and 1. A value close to 0 indicates the least similarity, while a value closer to 1 represents the highest similarity.

Challenges and Solutions
A common challenge that recommendation engines face is that the product rating data is quite sparse. Most users do not rate a product they use. Also, many products have too few ratings. A user versus product matrix obtained from such data results in a sparse matrix. Data scientists use techniques like matrix factorization to identify latent features from such sparse matrices which provide insights useful for making meaningful recommendations.
Generally, recommendation engines either use both or a combination of content-based and collaborative filtering methods to get around these issues.
Companies are increasingly using recommendation systems for personalized targeting of their customers and machine learning is increasingly being used in these solutions.
A few challenges that are peculiar to the fashion industry are that of color choices and the user size fit. The modern recommendation engines are getting around this by utilizing computer vision to determine the correct user size. Purchase history provides the data on the user’s size and color preferences.